


一段时间以来,我尝试创建一个网站,我会访问一个网站,打开浏览器的控制台获取需要的源代码。
后来我了解到可以用网页爬虫,于是开始用Node来抓取页面数据。
准备工作
我们需要准备以下3个包来做开发准备。
1)Axios(https://github.com/axios/axios)
Axios是一个基于Node.js的Promise的HTTP客户端,可以用它来抓取指定的网站。
2)Cheerio(https://github.com/cheeriojs/cheerio)
Cheerio是一个类似jQuyer但是以服务器运行的库。我们使用它选择从Axios返回来的内容。
3)Fs(https://nodejs.org/api/fs.html)
fs是一个node模块,用来把抓取到的内容加入一个JSON文件中。
开始开发
下面我们开始我们的项目。
首先创建一个文件夹,然后用cd命令进行该目录。
说明:我们使用系统的终端或命令行工具运行。
要初始化项目,先运行
npm init
然后进行如下步骤(你也可以同步进行输入)。如果你完成了初始化操作,下面就可以创建 package.json 文件。
接下来我们开始安装以下两个软件包:
npm install --save axios cheerio
请记住,fs如果安装过了,我们就不需要再重复安装一次了。
你可以在node_modules目录中看已经安装好的node插件包,也可以在package.json文件中看到该文件名。
从dev.to网站抓取内容
我们下面从 dev.to网站上下手,抓取该网站上的用户资料,它的用户资料URL是 https://dev.to/
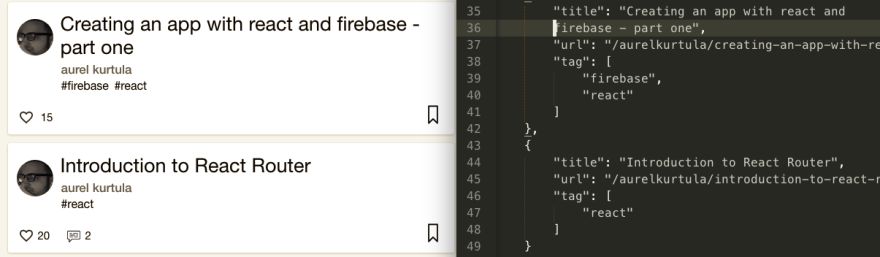
接下来在你的项目目录中创建一个JavaScript文件,我们称之为devtoList.js,如果你不喜欢可以换其它的名字。
第一步,我们引用已经安装好的node包:
let axios = require('axios')
let cheerio = require('cheerio')
let fs = require('fs')
下面我们开始抓取:
axios.get('https://dev.to/aurelkurtula')
.then((response) => {
if(response.status === 200) {
const html = response.data;
const $ = cheerio.load(html);
}
}, (error) => console.log(err) );
在该代码的第一行是指定抓取网站的URL地址。当开始抓取后,axios是基于承诺式的,then 分支便开始检查返回的内容是否正确,并且开始取得数据。
如果控制台日志 reponse.data 中你可以看到HTML标签。那我们将调入HTML给cheerio(jQuery已经隐含在其中的场景了)。如果要替换response.data,需要硬编码HTML。
const html = 'I have a bunch of questions on how to behave when contributing to open source
'
const h3 = cheerio.load(html)
console.log(h3.text())
接下将返回没有H3标签的字符串。
选择内容
接下来的重点是,你可以打开工作台中要查找要抓取的指定内容。如下HTML:
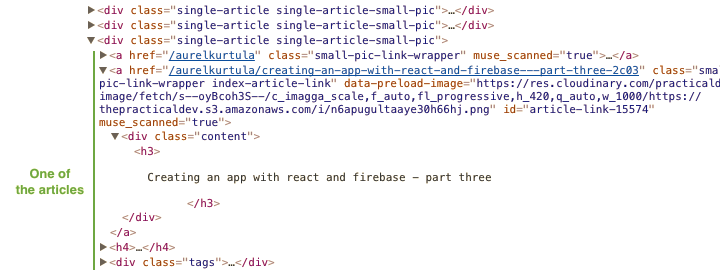
从上面的源代码中看到,我们看到文章是从single-article的类包含的,文章标题是在h3标签中。
进行如下的代码改造:
axios.get('https://dev.to/aurelkurtula')
.then((response) => {
if(response.status === 200) {
const html = response.data;
const $ = cheerio.load(html);
let devtoList = [];
$('.single-article').each(function(i, elem) {
devtoList[i] = {
title: $(this).find('h3').text().trim(),
url: $(this).children('.index-article-link').attr('href'),
tags: $(this).find('.tags').text().split('#')
.map(tag =>tag.trim())
.filter(function(n){ return n != "" })
}
});
}
}, (error) => console.log(err) );
上面的代码也很好理解,如果你看到了上面的参考图片,我们可以循环从.single-article类节点中抓取内容。如果我们查找到仅有h3标签,我们就使用trim()函数来删除一些空白空格。最后我们过滤一些空值。另外,我们通过锚标签中的href取得URL。
获取标签很简单,我们首先把它们当作一个字符串,如#tag #tag2,接下来把这些字符串分拆为数组。最后再将数据中的空格去除,最后再过滤掉所有空值。
我们声明了一个空数组 let devList = [] ,外部循环数据将放在此数组中。
开始执行。这个devtoList数据对象将保存着抓取的网站。现在我们将要存储的数据以JSON文件的格式使用。
axios.get('https://dev.to/aurelkurtula')
.then((response) => {
if(response.status === 200) {
const html = response.data;
const $ = cheerio.load(html);
let devtoList = [];
$('.single-article').each(function(i, elem) {
devtoList[i] = {
title: $(this).find('h3').text().trim(),
url: $(this).children('.index-article-link').attr('href'),
tags: $(this).find('.tags').text().split('#')
.map(tag =>tag.trim())
.filter(function(n){ return n != "" })
}
});
const devtoListTrimmed = devtoList.filter(n => n != undefined )
fs.writeFile('devtoList.json',
JSON.stringify(devtoListTrimmed, null, 4),
(err)=> console.log('File successfully written!'))
}
}, (error) => console.log(err) );
该原始 devtoList数组对象可能有空值,需要trim它们,接下来使用fs模块来写入到文件(前面我们命名为devtoList.json,数组对象的内容被转换为JSON格式)
以上爬虫源代码,可以在GitHub上找到:https://github.com/aurelkurtula/web-scraping
希望本篇文章的内容对你有用,假期愉快!
编译:陆晓龙
来源:21CTO社区


